System Prompt Caching Allows Broke Founder to Pay for Groceries
Last night, I noticed these emails where Anthropic was charging my credit card for $13-$15, multiple times a day.

When I dug into this more, I saw that yesterday I had 47M inputs tokens for Claude!

And it cost me ~$50. This was shocking because I recently switched to Claude Haiku 4.5 to avoid this precise issue.
Leonardo is a hungry beast for tokens.
I recently gave Leonardo the ability to write & run Rspec tests. And these tests take a lot of input tokens, especially if it's dumping all your SQL transaction queries into the LLM context window. 🤷
But beyond turning off verbose SQL statement logging to reduce the amount of input tokens, another thing stood out to me on Anthropic's pricing page.

Cached tokens are only $0.10 per million tokens! That's 1/10th the cost. That sounds amazing to me, so I decided to implement it into Leonardo's test building mode.
But first, let's just discuss costs and do an experiment.
Notice how many tokens this uses just to ask it to explore my project and tell me about it.


Claude Haiku ingested 139K of tokens. (The system prompt alone is 16K tokens).
BUT, notice it had 8 turns! Meaning, this system prompt got fed back into Claude Haiku 8 times! 16K * 8 = 128K tokens, just on ingesting the system prompt alone!
That single turn cost 15 cents. And as the conversation drags on, the cost skyrockets, because at each message, it continuously ingests the entire conversation, including all the previous tokens.
If this was Claude Sonnet, it'd be even more expensive. This 139K tokens would cost 45 cents. But just wait, it gets worse.

I then asked Leonardo to run Rspec, and the cost jumped up again. Now with 340,000 tokens, it cost 36 cents for this additional message from the user.
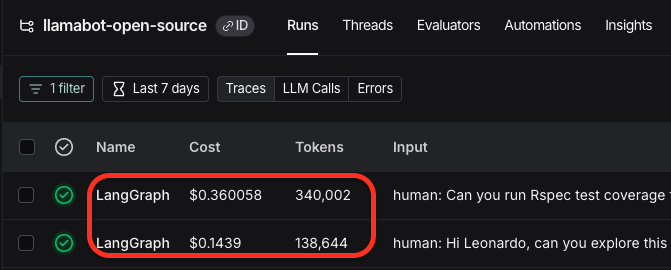
For Claude Sonnet, this would have been $1.08.
And now, this is where my budget for groceries really gets murdered: asking Leonardo to implement unit tests where there's gaps in coverage!

I asked Leonardo to implement new tests to boost test coverage. And Leonardo sent over 50!! messages, and implemented a handful of new tests using RSpec.

This run cost $2.48.
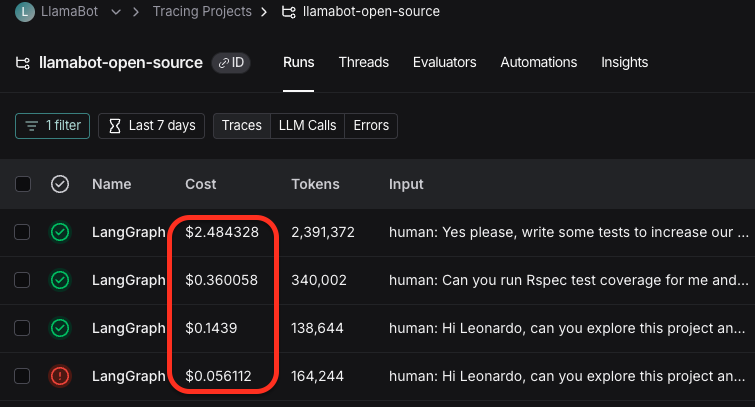
With Claude Sonnet, this would have been approximately $7.44.
Now, you can see how spending 12 hours on this yesterday, why I ended up with a bill of $47, (even when using the affordable Claude Haiku). This makes both me and my girlfriend sad. (Sorry babe, we have to cancel our plans to see Wicked 2, Leonardo ate all our money).
But.. I don't want to overly complain, because this is still pretty awesome.
Even if it's expensive, Leonardo generated 1,244 new lines of high quality Ruby/RSpec code that tests our Ruby on Rails project. It boosted test coverage and wrote over 80 new tests.
To do this, it ingested thousands of lines of code to understand the project well enough. I mean, just look at this beautiful Ruby code.

Pre LLMs, assume a Jr. Dev spent a full working day doing this. If you're paying said Jr. Dev a 75K/year salary, we're looking at ~$322.95 for that full days worth of work.
So even if we used Claude Sonnet, and it cost $10 for this, that's an order of magnitude lower on cost, and multiple orders of magnitude lower on time efficiency.
That being said, I'm a broke founder.
So if I'm choosing whether to pay API credits over paying my groceries (not hyperbole if this is $50/day in token costs), then I'm going with groceries so I don't starve.
Luckily, I can have my LLM tokens and eat them too, by implementing something called prompt caching.
The cost savings are dramatic, let me show you.
The main code change was to switch off LangChain's SystemMessage object, and use good ol' JSON.

At first, Claude Code tried to add in additional_kwargs={"cache_control": {"type": "ephemeral"}} as an input argument to the SystemMessage constructor, but I wasn't able to get it to trigger output.
In LangChain's documentation on Anthropic Caching, they actually have the example where they just use a JSON object for the system message, so that's what I decided to go with.
from langchain_anthropic import ChatAnthropic
model = ChatAnthropic(model="claude-sonnet-4-5-20250929")
messages = [
{
"role": "system",
"content": [
{
"type": "text",
"text": "Below is some long context:",
},
{
"type": "text",
"text": f"{long_text}",
"cache_control": {"type": "ephemeral"},
},
],
},
{
"role": "user",
"content": "What's that about?",
},
]
response = model.invoke(messages)
response.usage_metadata["input_token_details"]As a reminder, here's the costs without caching:
And here's the exact same experiment ran, but with caching enabled:

By just caching the system prompt, I cut the cost down to almost half of what it was previously!
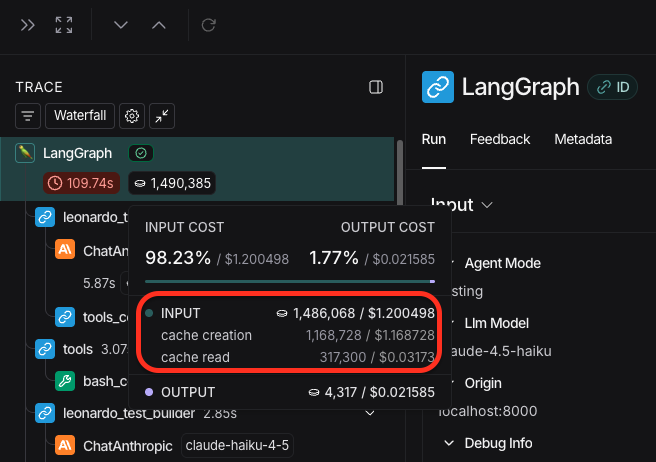
What's awesome too, is that I'm only caching the system prompt.
If I were properly caching the entire thread of messages, the cost would come down even more.
But, since I'm a lazy founder just trying to ship capability increases (such as making Leonardo 10x smarter for coding Ruby on Rails projects), I'll hold off on more LLM caching work until I get my next crazy high bill from Anthropic. 🙂
In summary, if you're a broke founder worried about the costs of groceries, yet you're hopelessly addicted to using Claude to write code, and especially if you're writing your own system prompts, consider implementing Anthropic's prompt caching mechanism.
With ❤️,
- Kody