TL;DR
- The cost to develop software has collapsed over the last 50 years — and demand has exploded.
- LLMs now let non-engineers build working software, but most AI builders break down during real project maintenance.
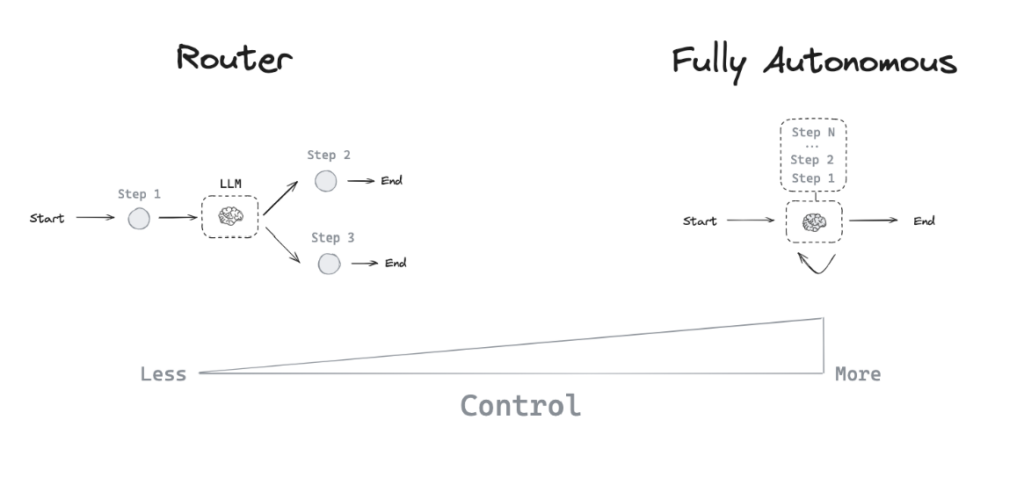
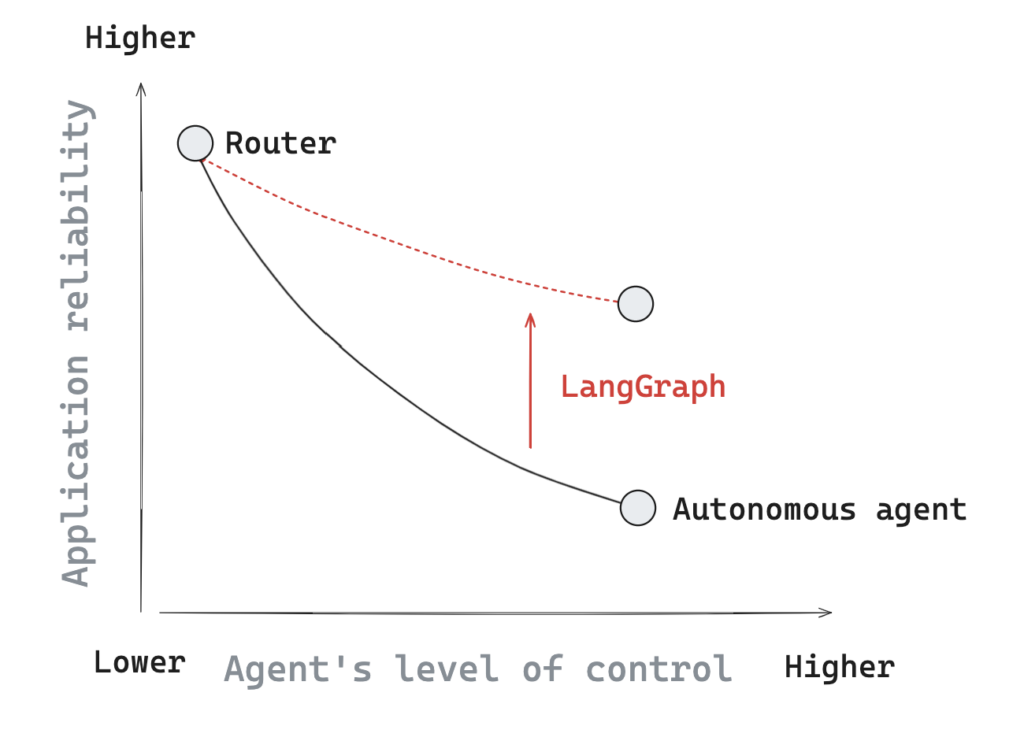
- Rails is uniquely suited for AI-driven development because it gives LLMs a deterministic, opinionated structure — the one thing AI agents need to reliably modify and maintain code.
- The remaining barrier is accessibility: Rails has historically been hard for non-technical people to install, run, or even start.
- Leonardo removes that barrier by giving users a zero-setup, browser-based Rails environment powered by an AI operator-agent — no terminal, no VSCode, no local environment required.
- Leonardo combines the accessibility of vibe-coding tools (Lovable/Bolt/Replit) with the power, stability, and maintainability of Rails.
- This is how the next 1,000,000 Rails apps will get created, by people who deeply understand real-world problems, not just engineers.
My goal: help accelerate the next 1 million next Rails apps be created, from non-traditional developers using LLMs.
Introduction: The cost to develop software has steadily decreased
Since 1970, the cost to develop software has plummeted. Higher level languages, better tooling, and sharing of knowledge has led to higher quality software that is more affordable.
Open Source frameworks & development infrastructure decrease the amount of time and effort to create new custom software.
It’s hard to objectively measure the cost to develop software. Counting the lines of code is misleading, because good engineers actually often write less code, and also comparing across programming languages and frameworks is misleading.
For example, to print Hello World in C is more lines of code than to print Hello World in a higher level language like Python. Here’s a good illustrative example on reading errors from a file.
High Level (Python):
Straightforward, expressive, hides the ugly parts:
count = 0
with open("log.txt") as f:
for line in f:
if "error" in line:
count += 1
print(count)
Lines of code: 6
Memory management: Automatic
I/O abstraction: Built-in
String ops: Built-in
Error handling: Could be added, but not required for basic functionality
Developer mental load: Minimal
Low Level (C):
You handle your own memory, buffers, file pointers, comparisons, and cleanup:
#include <stdio.h>
#include <string.h>
#include <stdlib.h>
int main() {
FILE *file = fopen("log.txt", "r");
if (file == NULL) {
perror("Error opening file");
return 1;
}
char *line = NULL;
size_t len = 0;
ssize_t read;
int count = 0;
while ((read = getline(&line, &len, file)) != -1) {
if (strstr(line, "error") != NULL) {
count++;
}
}
printf("%d\n", count);
free(line);
fclose(file);
return 0;
}
Lines of code: ~35
Memory management: Manual (free, malloc via getline)
I/O: Manual (fopen, getline, fclose)
String ops: Manual (strstr)
Error handling: Required
Developer mental load: High — and mistakes cause security bugs
____
While this example illustrates how software has gotten easier, this also helps illustrate why lines of code as an objective metric is misleading.
To solve this problem, an engineer from IBM Allan Albrecht, invented function point analysis.
Albrecht’s insight was to measure the size of the problem being solved, not the amount of code used to solve it.
So he created the now-standard 5 categories:
- External Inputs
- External Outputs
- External Inquiries
- Internal Logical Files
- External Interface Files
Weighted → summed → Function Points.
Software companies have also tracked & published data around their own function points, so we have some reference as to how this has evolved over time. While there’s no comprehensive data source created, we can still derive a rough approximation of cost per function point over time, since the 70s.
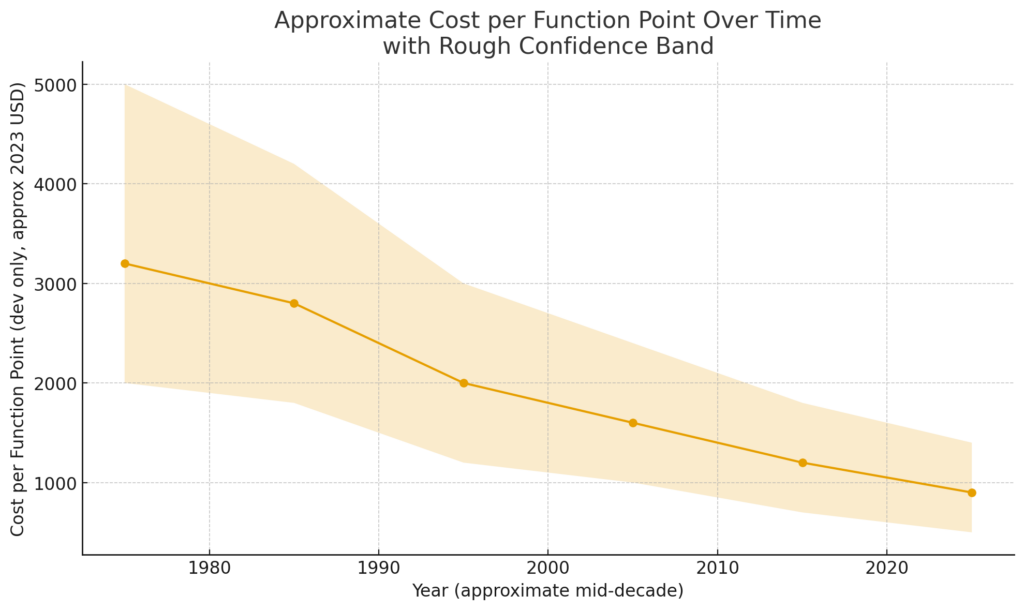
Sources: Capers Jones, The Economics of Software Quality, and ISBSG / Czarnacka-Chrobot (case study using ISBSG “Software Project Costs”).
It’s safe to claim that since the 1970s, the cost has dropped approximately by a factor of 3, despite growing costs of labor for software engineers.
These productivity gains come from better tooling, open source projects, online knowledge sharing, and the rise of higher level programming languages like Python, Ruby, and JavaScript.
As is true for any technology: as the cost decreases, the demand increases.
Demand for New Software is Still Growing.
The world has a plethora of problems that can still be addressed by new software. But the cost to develop new software has always been a bottleneck, because engineers are expensive, and code is complicated.
With the costs to develop new software decreasing, along with new AI capabilities such as AI vision, LLMs, and generative AI, we can now build software that was previously unimaginable, for much cheaper than ever before in history.
Increasingly, software isn’t being created by just professional developers. A new class is emerging, known as “citizen developers.” This class of people do not have Computer Science degrees, and they rely increasingly on other tools to generate code for them.
Before LLMs, a plethora of no-code and low-code tools like Bubble, Make, and even open source projects like WordPress made building new software accessible. But as AI scaled, LLMs have become extremely good at writing code.
LLMs help non-engineers build software.
This has led to an explosion in popularity of “vibe coding” tools, such as Lovable.dev, Bolt.new, and Replit. You can simply type your idea into an AI chat box, and have a fully functioning software prototype in a matter of seconds.
But LLMs writing code isn’t all sunshine and roses, there are difficult problems that arise, such as:
Expensive Token Costs & High Usage
- Credit Consumption: Users frequently find themselves burning through credits for simple tasks. “I burn through credits for what should be simple tasks.”
- Costly Debugging: Debugging issues can be expensive due to high token usage. “I’ll end up fixing bugs for the next 50 credits.”
Bugs are Inevitable and Hard for LLMs to Fix
- Broken Functionality: The AI often breaks things, making the app just not… well, work. “The AI breaks things, a lot, when it should be obvious I don’t want it broken.”
- Hallucinations and Errors: LLMs often guess at solutions, leading to incorrect fixes and actually causing more problems. “The AI guesses too much.”
- Complex Integrations: Integrating with external services like Stripe can be challenging. “Stripe integrations / API integrations”
Security and Auth
- Authentication Issues: Implementing robust user authentication is often problematic. “User authentication is a foundational basic included in practically every SaaS. It’s insane the Lovable doesn’t have robust, elegant, best-practice implementation of this by default.”
- Security Policies: Managing Row-Level Security (RLS) and user permissions can be daunting. “RLS policies and wrong user permissions should be checked, double-checked, advised on, or resolved by default.”
Scalability and Performance
- Limited Full-Stack Capabilities: Many tools struggle to build full-stack applications with complex logic. “only concern is they dont build fullstack really.”
- Performance Issues: Applications built with these tools can sometimes be slow or unresponsive. “Bolt started, and it created something that I videoed of it working, now I tried to create the first account and nothing happened which is stressful”
User Experience and Learning Curve
- Complex Learning Curve: Users may find the tools difficult to learn, especially if they have no coding background. “I’m worried the learning curve is too steep for a non-coder like me.”
- Generic Designs: The tools often produce generic-looking applications. “all vibe coded land pages look the same..haha. mine is nearly the same.”
Integration and Export
- Code Export Issues: Exporting code from these platforms can be problematic, making it hard to integrate with other tools or workflows. “Bolt is still download zip or move between apps.”
- Limited Customization: Customizing and extending the generated code can be challenging. “The generated code often breaks when you try to customize or extend it”
Community and Support
- Lack of Community: Users may struggle to find help or resources when they encounter issues. “I have shared the video to my Facebook profile paulgallant1 and YouTube as well and here.”
- Inconsistent Support: Support for these tools can be inconsistent, leading to frustration. “The support is just ok but the tool is straight forward”.
But despite these problems, millions of “citizen developers” are continuing to adopt and pay for AI generated coding tools. As AI models become increasingly affordable and capable, these problems will become easier to solve.
Another way we can reduce these errors is by helping the LLM out, the same way we’d help a Jr. Software Engineer out: give it the right tools. That’s where a framework like Ruby on Rails comes into play.
My Thesis: Rails is the perfect framework for non-engineers to build software using LLMs
There are very strong, structural advantages of Ruby on Rails, as explained by it’s creator David Heinemeier Hansson:
It brings us to the ideal of The One Person Framework. A toolkit so powerful that it allows a single individual to create modern applications upon which they might build a competitive business. The way it used to be.
There’s so much to learn these days, if you want to be an expert in all the latest tools and techniques. The conventional path [to software engineering], as paved by solutions extracted from giant tech companies, is a journey akin to The Oregon Trail. You might well die of dysentery before you ever get to your destination!
Rails 7 seeks to be the wormhole that folds the time-learning-shipping-continuum, and allows you to travel grand distances without knowing all the physics of interstellar travel. Giving the individual rebel a fighting chance against The Empire.
You simply can’t play by the same rules against an opponent exponentially stronger than you.
The key engine powering this assault is conceptual compression. Like a video codec that throws away irrelevant details such that you might download the film in real-time rather than buffer for an hour.
Source: The One Person Framework, David Heinemeier Hansson, Creator of Rails

Rails + LLMs Are A Perfect “Unfair Leverage Stack”.
If a non-engineer is going to build real software with an AI assistant, Rails is simply the highest-probability path to success.
Why?
- Rails has batteries-included: migrations, ActiveRecord, jobs, mailers, caching, etc.
- Rails already embodies 20 years of engineering best practices, so the LLM doesn’t have to reinvent fundamentals.
- Convention over configuration massively reduces hallucination surface area.
- Rails gives LLMs a predictable file structure, which is critical for deterministic code modifications.
- Rails’ monolith avoids the fragility of microservice-style code generation.
- Rails robust ecosystem of Gems such as Devise for security/auth patterns reduce catastrophic LLM mistakes, and provide powerful, working code, on day 1.
Non-engineers using LLMs do not want:
- Modern JS dependency churn
- 18 dependencies for basic CRUD
- Vite → Next → Bun → Node → pnpm → esbuild → whatever
They want:
- One framework
- One mental model
- One cohesive toolkit
The Rails superpower is not just technical — it’s psychological. It removes 80% of the cognitive load that overwhelms not only engineers, but also LLMs.
This is a truth nobody in the JavaScript hype cycle wants to admit, and it’s exactly why Rails is superior for AI coding agents.
The Real Problem Isn’t Code Generation — It’s Project Lifecycle
Existing vibe coding tools can generate code, but cannot maintain code.
That’s their fatal flaw.
LLMs fall apart when:
- File structures change unpredictably
- Auth patterns drift
- API shape diverges
- The app becomes a tangle of idiosyncratic user prompts
Rails solves this by giving the LLM:
- Deterministic MVC structure
- Deterministic naming conventions
- Deterministic routing
- Deterministic file placement
LLMs thrive when the environment is deterministic. Rails is deterministic.
But determinism alone isn’t enough.
Ruby on Rails has always had one major weakness: it’s hard to start. Rails is unbelievably productive once you’re inside it, but getting there traditionally requires terminals, version managers, local databases, and dev environments that instantly overwhelm non-technical people.
This is the real reason browser-based AI coding tools exploded.
Not because their stacks are better, but because they’re accessible.
Cursor and Claude Code are incredible tools, but most people don’t have VSCode installed. Most have never touched a terminal. They see a blinking prompt and shut their laptop.
This is where tools like Lovable.dev, Bolt.new, and Replit actually shine: they’re frictionless.
You click a button and you’re building software in the browser.
No installs. No setup. No environment debugging.
My 63-year-old mother could start a project that way.
Rails doesn’t have this yet.
If Rails is going to empower a new class of builders — if the next million Rails apps will be created by people outside traditional engineering — then Rails needs something radically simpler:
- A brand-new Rails app that spins up instantly in the browser
- Zero installation or local environment
- A simple chat interface where they never have to view or edit the code manually
You need an AI agent that can operate Rails (run it, modify it, migrate it, refactor it, etc.) inside a stable environment where the user never touches the terminal.
This is exactly what Leonardo provides.
Leonardo runs a full Rails app in the cloud, accessible entirely through the browser. It gives users a chat interface to create and modify features without ever installing Ruby, opening VSCode, or configuring PostgreSQL.
And because Rails is a monolith (concise, high-level, migration-aware, schema-aware), Leonardo’s agent can maintain the app over time without collapsing it. It doesn’t rely on Supabase or an external backend. It doesn’t generate sprawling TypeScript/React projects that explode token usage. Rails is far more token efficient and far more structurally predictable for an LLM.
We also did something fundamentally different with pricing:
users pay exactly the LLM token cost, no markup.
Or they can bring their own API keys entirely.
This makes Leonardo dramatically more cost-effective than Lovable, Bolt, or Replit. But, more importantly, Rails + Leonardo produces software that is maintainable, stable, and evolvable.
Leonardo gives you the accessibility of browser-based AI builders…
with the power, determinism, and maintainability of Ruby on Rails.
This is the missing layer the ecosystem needed.
For the first time in history, the bottleneck to building software is no longer technical. It’s imaginative. The world is full of people who understand business problems deeply, but cannot code. If we give them a stable, powerful, opinionated framework, we unlock a new class of builders!
The next million Rails apps will not come from Silicon Valley dev teams. They will come from accountants automating workflows, operations leads replacing spreadsheets, founders validating ideas, and domain experts who’ve never touched a terminal.
If you’re a founder, operator, freelancer, or domain expert with a problem you wish were automated, then build it with Rails and an AI partner. Leonardo is the first step.
Use Leonardo here: https://llamapress.ai








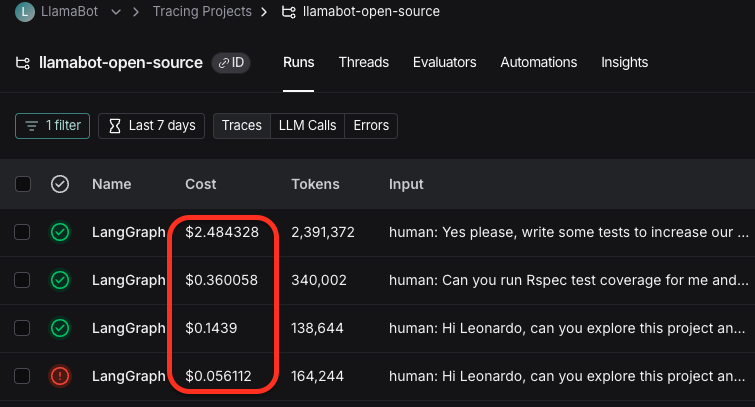



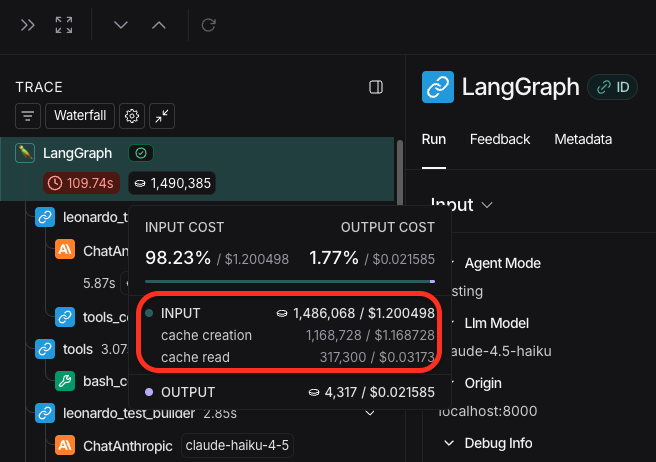







![```
@tool
def read_rails_file(filepath: str) -> str:
"""Read the contents of a Rails file."""
# Construct the full path
full_path = APP_DIR / "rails" / filepath
# Check if file exists
if not full_path.exists():
return f"File not found: {filepath}"
# Read the file contents
try:
# Option 1: Using pathlib (recommended)
contents = full_path.read_text()
# Option 2: Using traditional open()
# with open(full_path, 'r') as f:
# contents = f.read()
return contents
except Exception as e:
return f"Error reading file: {e}"
@tool
def list_directory_contents(directory: str = "") -> str:
"""
List the contents of a directory.
If directory is empty, lists the rails root directory.
"""
# Build path - if directory is empty, just use rails root
dir_path = APP_DIR / "rails" / directory if directory else APP_DIR / "rails"
if not dir_path.exists():
return f"Directory not found: {dir_path}"
return os.listdir(dir_path)
# Global tools list
tools = [list_directory_contents, read_rails_file]
# System message
sys_msg = SystemMessage(content=f"""You are Leonardo,
a Llama that can read and write changes to a Ruby on Rails application.
Your task is to help the user with their Ruby on Rails application,
by answering questions, making modifications, etc.
You can list the contents of the Rails directory to explore the app.
""")```](https://www.kodykendall.com/wp-content/uploads/2025/08/Screenshot-2025-08-19-at-10.10.11 AM.png)