Playwright is a powerful tool for our AI Agent. Playwright can launch a browser that can be controlled via Python code.
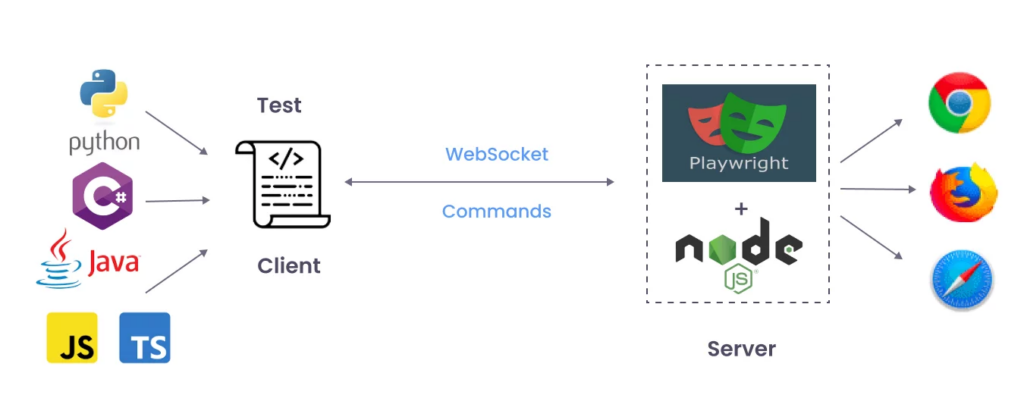
It can do the following:
- Query HTML/CSS elements and interact with the browser dom.
- Take screenshots of the page it’s viewing.
- View JavaScript logs
Why is giving Playwright to our coding agent useful?
- Our agent could use Playwright to take screenshots and recreate it as HTML/CSS.
- Our agent could inspect HTML page DOMs & styling.
- Our agent could dynamically test the code we’re building in real time, (as if it were a human).
- It could detect if our page wasn’t loading, read JavaScript logs, and feed it back into the agent in a type of “self-healing” verification loop.
- (This is what real web software developers do, they load the browser and test the app in real time as they’re building it out).
- It could detect if our page wasn’t loading, read JavaScript logs, and feed it back into the agent in a type of “self-healing” verification loop.
Challenges with Directly Copying HTML/CSS Source
While we can do that, these files can often be extremely massive. And they are transpiled
While directly copying HTML and CSS from existing websites seems straightforward, this comes with challenges. Modern web pages, particularly those built with no-code platforms or advanced page builders (like Wix, SquareSpace, Elementor, etc.), typically produce large, complex, and heavily transpiled codebases. This includes heavy, excessive CSS styles, many nested elements, and hugely bloated JavaScript files.
This causes:
Massive File Sizes: Transpiled code from visual builders is enormous, making it difficult for Language Learning Models (LLMs) or agents to parse efficiently. Current LLMs have input token limits, restricting the amount of content they can understand and process at once.
Edibility: We’re not looking to infringe on copyrighted work, so we’ll need to be able to make our own derivations from this, ideally using the LLM. But copied code from these tools often lacks readability and is challenging to edit or debug, leading to difficulties for the LLM to understand it, let alone make effective changes.
Instead, a vision first approach, along with passing in a parsed down version of their HTML structure helps generate clean, understandable, and editable code, overcoming these direct-copy challenges effectively.
Using AI Vision for Web Page Cloning is Now Possible Due to the Latest Advancements in AI Vision Reasoning Capabilities.
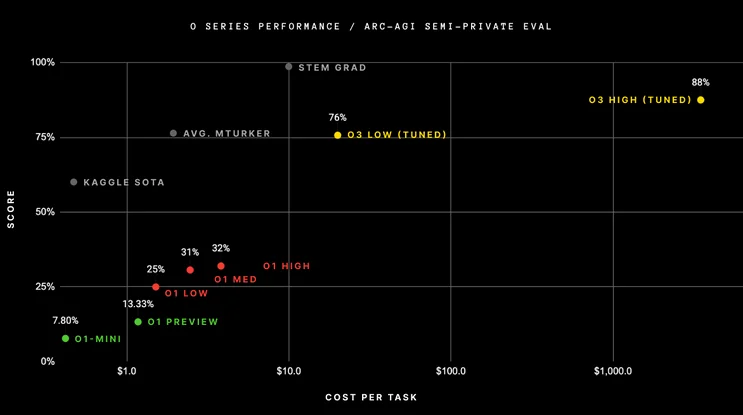
AI models have gotten really good at visually reasoning about image information. Take OpenAI’s announcement back in December 2024, about O3’s breakthrough in visual reasoning tasks, such as the ARC AGI data-set.
ARC AGI is an evaluation set to compare AI systems performance against. It was intended to be a set of questions and tasks that would be very challenging for AI models to solve, and it’s creators didn’t anticipate a solution to appear as rapidly as it did.
See the announcement here:
We want to test the models ability to learn new skills on the fly. … ARC AGI version 1 took 5 years to go from 0% [solved] to 5% [solved]. However today, O3 has scored a new state of the art score that we have verified. O3 was able to score 87.5%, human performance is comparable at 85% threshold, so being above this is a major milestone.
Gregory Kamradt, president of the ARC foundation.

Given these breakthroughs, an AI model like O3 should be able to reason about the image we give it, and provide a very clear verbal representation of webpage, that can then be passed in to another LLM to create the HTML/CSS code.
Our Approach to Cloning WebPages using AI, and our Agent Architecture:
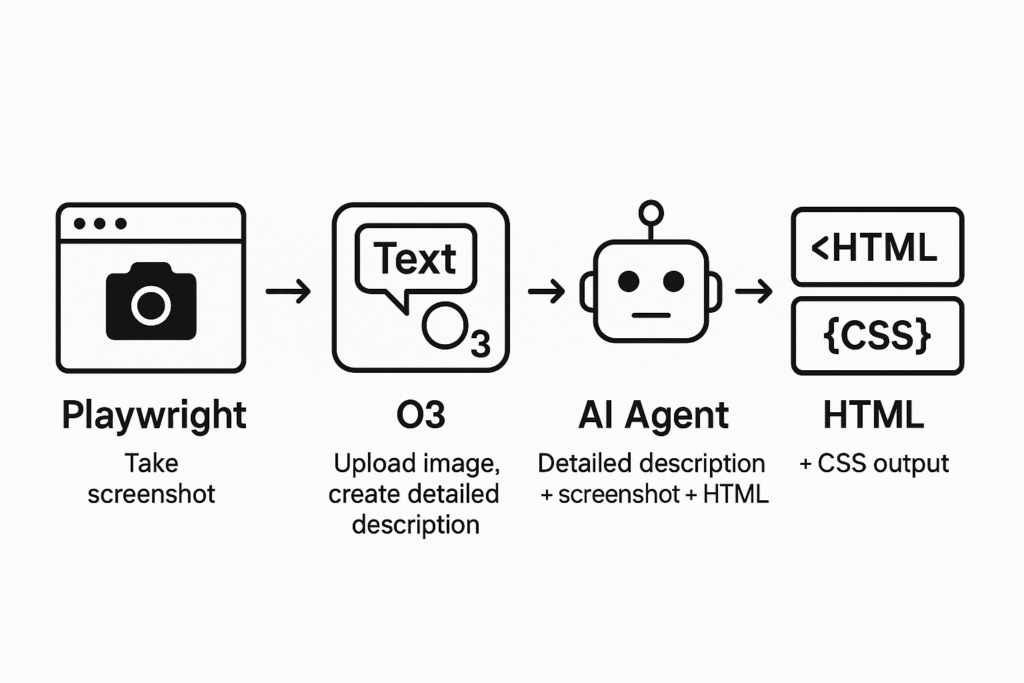
Here’s the video going over the implementation!
06/04/2025, 7:59PM:
Feeling a little discouraged! I made the decision to add the playwright screenshot in as a two-step tool-calling process. (two new additional tools).
That means our agent has the following tool calls at its disposal:
- Write HTML
- Write CSS
- Write JavaScript
- get_screenshot_and_html_content_using_playwright
- clone_and_write_html_to_file
There are two main problems happening right now.
- The LLM is correctly picking “get_screenshot_and_html_content_using_playwright” when I send in a prompt like
Please clone this webpage: https://fieldrocket.us
2. The LLM is not including image sources for some reason, even though the trimmed_html that we get from playwright, does indeed have the image src tags included in the HTML.
Furthermore, our tracing is lame because when we get into our clone_and_write_html_to_file, we aren’t using langchain_openai sdk, so it’s not logging the LLM input & output in LangSmith (making it harder to observe & debug)

But, roughly 30% of the time, it’s jumping straight from the get_screenshot tool call, into the write_html tool call, rather than going to the clone_and_write_html_to_file.
It does make me wonder: what does this @tool decorator even do?
Is the LLM just seeing the function name of the tool call, or is it also seeing the comment just below the method signature? In the LangChain academy course on LangGraph, Lance doesn’t specify. But he has the comment in there right below the signature, so I assumed the LLM could see it.
According to this guide
You must include a docstring which will serve as the function description and help LLM in understanding its use.
Which is what I assumed, and how Lance appeared to present it in the LangChain academy course.
One workaround that could work, is collapsing the two separate tool-calls into a single one. That way the LLM isn’t having to make one right decisions, just a single right decision.
I bet that would solve this first problem.
I now collapsed the two separate tools into one:
@tool
def get_screenshot_and_html_content_using_playwright(url: str) -> tuple[str, list[str]]:
"""
Get the screenshot and HTML content of a webpage using Playwright. Then, generate the HTML as a clone, and save it to the file system.
"""
html_content, image_sources = asyncio.run(capture_page_and_img_src(url, "assets/screenshot-of-page-to-clone.png"))
llm = ChatOpenAI(model="o3")
# Getting the Base64 string
base64_image = encode_image("assets/screenshot-of-page-to-clone.png")
print(f"Making our call to o3 vision right now")
response = llm.invoke(
messages=[
SystemMessage(content="""
### SYSTEM
You are “Pixel-Perfect Front-End”, a senior web-platform engineer who specialises in
* redesigning bloated, auto-generated pages into clean, semantic, WCAG-conformant HTML/CSS
* matching the *visual* layout of the reference screenshot to within ±2 px for all major breakpoints
When you reply you MUST:
1. **Think step-by-step silently** (“internal reasoning”), then **output nothing but the final HTML inside a single fenced code block**.
2. **Inline zero commentary** – the code block is the entire answer.
3. Use **only system fonts** (font-stack: `Roboto, Arial, Helvetica, sans-serif`) and a single `<style>` block in the `<head>`.
4. Avoid JavaScript unless explicitly asked; replicate all interactions with pure HTML/CSS where feasible.
5. Preserve all outbound links exactly as provided in the RAW_HTML input.
7. Ensure the layout is mobile-first responsive (Flexbox/Grid) and maintains the same visual hierarchy:
e.g) **header ➔ main (logo, search box, buttons, promo) ➔ footer**.
### USER CONTEXT
You will receive two payloads:
**SCREENSHOT** – a screenshot of the webpage.
**RAW_HTML** – the stripped, uglified DOM dump (may include redundant tags, hidden dialogs, etc.).
### TASK
1. **Infer the essential visual / UX structure** of the page from SCREENSHOT.
2. **Cross-reference** with RAW_HTML only to copy:
* anchor `href`s & visible anchor text
* any aria-labels, alt text, or titles that improve accessibility.
3. **Discard** every element not visible in the screenshot (menus, dialogs, split-tests, inline JS blobs).
4. Re-create the page as a **single HTML document** following best practices described above.
### OUTPUT FORMAT
Return one fenced code block starting with <!DOCTYPE html> and ending with </html>
No extra markdown, no explanations, no leading or trailing whitespace outside the code block.
Here is the trimmed down HTML:
{trimmed_html_content}
"""),
HumanMessage(content=f"Here is the trimmed down HTML: {trimmed_html_content}"),
HumanMessage(content=f"data:image/jpeg;base64,{base64_image}")
]
)
breakpoint()
with open("/Users/kodykendall/SoftEngineering/LLMPress/Simple/LlamaBotSimple/page.html", "w") as f:
f.write(response.content)
return "Cloned webpage written to file"Let’s try it now.
Leave a Reply